CONCUR: Controlling Mid-Phase Thrashing in Agentic Batch Inference
Batch inference for LLMs used to be shaped by requests. A request arrives, the server schedules prefill and decode, the KV cache grows for that sequence, and the request eventually leaves.
Agentic workloads are different. An agent is not one request. It is a long-running loop of planning, tool calls, observations, and follow-up generations. Many agents can stay alive at the same time, and each one gradually accumulates KV state. The server may still see individual requests, but the resource pressure is created by agent lifetimes.
CONCUR focuses on the pathology that appears in this setting: mid-phase thrashing.
What Is Mid-Phase Thrashing?
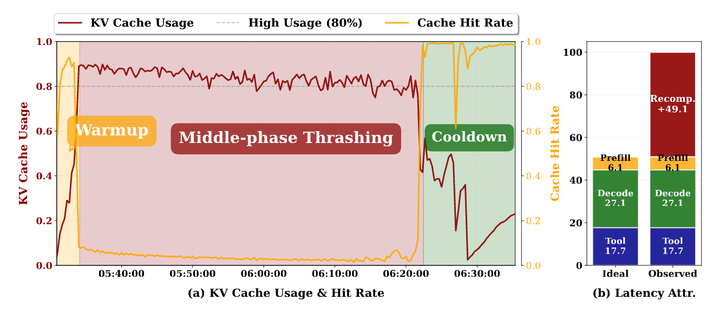
A long-running batch of agents does not fail immediately. At the beginning, most agents have short histories, KV cache demand is modest, and throughput looks healthy. Near the end, many agents have already completed, so pressure drops again.
The hard part is the middle.
In the mid phase, many agents are still active and their histories have grown. The aggregate KV cache footprint becomes large, but the GPU memory may not be completely exhausted yet. This is what makes the problem subtle: the system can look feasible by a capacity check, while the cache is already becoming inefficient.
When KV pressure crosses a threshold, request-level cache management starts fighting itself. A serving system may evict old KV blocks to make room for new ones. But agentic workloads soon return to those evicted histories, because the same agents keep generating, calling tools, and continuing. The server then has to recompute or reload context, which consumes GPU time and causes more cache churn. More churn leads to more eviction. More eviction leads to more recomputation. Throughput collapses before memory capacity is formally exhausted.
That collapse is mid-phase thrashing.
Why Request-Level Control Is Too Late
The root cause is a mismatch of control granularity. The serving runtime manages individual requests, but the pressure source is the number of active agents.
If too many agents are admitted together, each agent continues to grow its own history. A reactive cache policy can only respond after the KV cache is already congested. LRU-style eviction may be locally reasonable for a single request stream, but it is a poor global signal for agentic workloads. It does not know that an evicted block belongs to a still-living agent that will likely need it again soon.
In other words, the system is not just running out of memory. It is admitting too many long-lived state machines into a shared cache.
CONCUR changes the question from “which KV block should we evict now?” to “how many agents should be active at the same time?”
| Control point | What it sees | Why it is too late or useful |
|---|---|---|
| Request-level cache policy | Individual KV blocks and request streams | Reacts after congestion has already started |
| Static batch sizing | Initial workload shape | Misses the fact that agent histories grow over time |
| Agent-level admission | Number of active long-lived agents | Acts on the entity that accumulates state |
Agent-Level Admission Control
CONCUR adds a lightweight control layer above the LLM serving engine. It does not replace the backend cache manager. Instead, it regulates agent admission so the aggregate active-agent pressure stays below the point where cache efficiency collapses.
The design borrows the spirit of congestion control. The KV cache is treated as a shared bottleneck resource, and the number of concurrently active agents becomes the control window. When runtime cache signals indicate the system is healthy, CONCUR increases concurrency to use more capacity. When the signals show congestion, it backs off before thrashing takes over.
This is closer to AIMD-style control than static batching. Additive increase lets the system cautiously probe for more parallelism. Multiplicative decrease reacts quickly when cache pressure becomes dangerous. The important detail is that the control unit is an agent, not a request. Pausing admission of new agents preserves execution continuity for already-admitted agents and avoids repeatedly evicting the histories they will soon reuse.
This proactive control also preserves compatibility. Existing LLM serving systems can continue to manage request scheduling and KV placement internally. CONCUR only decides how many agents should be allowed into the active set based on cache-aware feedback.
Why It Works
Mid-phase thrashing is caused by cumulative state pressure, so the solution has to act before the cache reaches the thrashing regime. By bounding active agents, CONCUR reduces the number of long-lived contexts competing for KV cache at once. The system may run fewer agents concurrently, but each active agent experiences less eviction and recomputation, so useful generation throughput improves.
The paper reports that CONCUR prevents mid-phase thrashing across large models and real-world agent workloads, improving batch inference throughput by up to 4.09x on Qwen3-32B and 1.9x on DeepSeek-V3.
What CONCUR buys.
- It prevents the mid-phase collapse caused by eviction/recomputation feedback.
- It improves batch inference throughput by up to 4.09x on Qwen3-32B.
- It improves throughput by 1.9x on DeepSeek-V3.
The lesson is simple but easy to miss: for agentic inference, the right scheduling object is not always the request. Sometimes the request is only a symptom. The agent is the entity accumulating state, consuming cache over time, and returning to the same history again and again. CONCUR makes that entity visible to the serving system.
Paper: CONCUR: High-Throughput Agentic Batch Inference of LLM via Congestion-Based Concurrency Control
Preprint: arXiv:2601.22705
Zhisheng YE
Machine Learning Systems Researcher
My research interests include AI Infra for LLMs, algorithm–system co-design for machine learning systems and resource management.