GPU Cluster Scheduling: A Map for Deep Learning Workloads
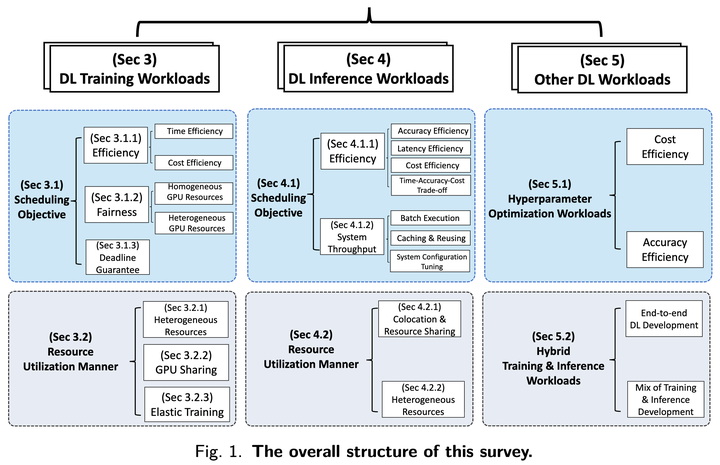 A taxonomy of deep learning workload scheduling in GPU datacenters
A taxonomy of deep learning workload scheduling in GPU datacenters
GPU cluster scheduling is easy to underestimate. At first glance, it looks like a familiar resource allocation problem: jobs arrive, GPUs are free or busy, and the scheduler decides who runs next.
Deep learning breaks that simplicity.
Training jobs can run for days, need gangs of GPUs, and care deeply about placement topology. Inference services are online, latency-sensitive, and often underutilize a GPU unless requests are batched or colocated. Hyperparameter tuning launches many similar trials, most of which are meant to be discarded. LLM workloads add model parallelism, massive memory footprints, long contexts, and bursty development patterns.
Our survey, Deep Learning Workload Scheduling in GPU Datacenters, tries to organize this messy design space. The most useful way to read the field is not as a list of schedulers, but as a set of tensions: speed versus cost, utilization versus isolation, fairness versus efficiency, and online latency versus cluster-wide throughput.
Why DL Scheduling Is Different
Traditional HPC and big-data schedulers provide useful starting points, but DL workloads have their own physics.
Training jobs are often gang-scheduled. A distributed job needs all requested GPUs at the same time, so GPUs are not easily divisible like CPU slots. Placement matters because communication-heavy jobs may run much faster when GPUs are packed within a node or connected by NVLink rather than scattered across weaker links. Preemption is expensive because model and optimizer states are large. At the same time, training is iterative, so a few profiled iterations can often reveal throughput, memory behavior, and placement sensitivity.
Inference has nearly opposite pressure. Each request is small compared with a training job, but the service has latency SLOs. Batching improves GPU utilization, yet waiting too long to form a batch hurts latency. Colocation improves throughput, yet interference can violate tail latency. The scheduler has to trade average efficiency against worst-case user experience.
This is why GPU cluster scheduling is not one problem. It is a family of related problems whose correct answer depends on the workload.
Training: Efficiency, Fairness, Deadlines
For training workloads, the survey groups scheduling objectives into three broad categories.
The first is efficiency. Some schedulers reduce job completion time through priority rules, such as least attained service or progress-aware variants. Others use profiling or learning-based methods to predict job duration, speed, placement sensitivity, or future resource needs. Placement is a core part of efficiency: a scheduler can have enough GPUs in aggregate but still produce poor performance if it fragments the cluster and cannot satisfy locality.
The second is fairness. Fairness is subtle because GPUs are indivisible in common gang-scheduling settings, and heterogeneous GPUs do not provide equal value to every job. Finish-time fairness, long-term GPU-time fairness, and heterogeneity-aware fairness all try to answer a version of the same question: how much service did this job or tenant deserve, and how much did it actually receive?
The third is deadline guarantee. Deadline-aware training is less explored, but important for production workflows. A best-effort job can tolerate delay; an SLO job cannot. Systems in this direction need to predict whether a job can finish before its deadline under different placements and resource allocations, then decide how to mix deadline jobs with normal jobs.
Training: How GPUs Are Used
Objectives are only half the taxonomy. The other half is how a scheduler uses resources.
Heterogeneous resource scheduling recognizes that “a GPU” is not a uniform unit. Different model architectures benefit differently from newer GPU generations, CPU allocation, memory, network bandwidth, and storage. A cost-effective scheduler should place jobs where their bottlenecks match the available hardware, not blindly send every job to the newest device.
GPU sharing attacks the underutilization problem. Many training jobs cannot saturate a modern GPU. Packing multiple jobs onto one device through MPS, MIG, virtualization, time sharing, or framework-level co-execution can improve utilization. The risk is interference: the scheduler must know when sharing helps and when it silently slows everything down.
Elastic training changes the number of GPUs assigned to a job over time. This can reduce queueing and improve utilization, especially when demand fluctuates. But elasticity is not free. Resource changes may require checkpointing, reinitialization, or batch-size adaptation. If batch size changes affect convergence, a scheduler may improve system throughput while quietly changing model behavior.
The broad lesson is that training schedulers increasingly need to be co-designed with training frameworks. The scheduler wants fine-grained control, but the framework knows whether a job can safely pause, resize, share, or change batch size.
Inference: Latency, Cost, Throughput
Inference scheduling is shaped by a different triangle: latency, cost, and accuracy.
Latency is usually the first-class constraint. A model serving system can improve throughput by batching requests, but a request waiting in a queue is still user-visible latency. A practical scheduler often uses dynamic batching: increase batch size when the service is healthy, shrink it when latency approaches the SLO.
Cost enters through cloud instance choice, autoscaling, and heterogeneous hardware. Some workloads are cheaper on CPU, some need GPU, and some become cost-efficient only when batching is large enough. The scheduler has to decide not only where to run a model, but how many replicas and which instance types are worth paying for.
Accuracy adds another axis. Some systems choose among model variants, ensembles, or modalities. A smaller model may be cheap and fast but less accurate; a larger model may be slower but better. This turns inference scheduling into a policy problem: what accuracy loss is acceptable for a given latency or cost budget?
Throughput techniques include batching, caching, model residency, and colocation. But inference colocation is more dangerous than training colocation because SLO violations are immediate. A scheduler needs interference models, isolation mechanisms, or hardware partitioning to make sharing safe.
Beyond Training and Inference
Some workloads deserve their own category.
Hyperparameter optimization is technically training, but operationally different. It launches many similar trials, prunes weak ones, and shifts resources toward promising configurations. This structure creates opportunities for early stopping, elastic trial allocation, trial packing, model fusion, and surrogate-based tuning. Our Hydro work is one example: it uses model scaling, trial fusion, and cluster-level interleaving to make HPO less brute-force.
Mixed training and inference workloads are another frontier. Inference clusters are often overprovisioned for bursts, leaving idle GPUs during low-traffic periods. Training jobs can sometimes borrow that capacity if the system can preempt or resize them quickly when inference demand returns. The challenge is respecting online SLOs while reclaiming otherwise wasted capacity.
These cases point to a larger trend: future schedulers will be more workload-aware. A generic GPU queue is too blunt for the diversity of DL development.
Where the Field Is Going
The survey ends with three research directions that still feel current.
First, emerging workloads will keep changing scheduler design. LLM pretraining, fine-tuning, serving, agentic inference, and HPO all expose different bottlenecks. The scheduler must understand more than GPU count; it must understand memory pressure, communication structure, context length, trial similarity, and elasticity.
Second, scheduling decisions need better intelligence. Heuristics are robust and deployable, mathematical optimization can be principled but slow, and ML/RL-based schedulers can capture complex patterns but are hard to trust and benchmark. A practical scheduler may combine all three: heuristics for the fast path, profiling for calibration, and optimization or learning for difficult decisions.
Third, hardware heterogeneity is becoming unavoidable. A production cluster may contain multiple GPU generations, specialized interconnects, CPUs, storage tiers, and accelerators. Heterogeneity creates opportunities for better cost-performance, but it also complicates fairness. Allocating an old GPU and a new GPU for the same amount of wall-clock time is rarely equal service.
The simplest summary is this: GPU scheduling is no longer just about filling empty slots. It is about matching workload structure to hardware structure under user-visible objectives.
That is what makes the area interesting. The best scheduler is not merely the one with the shortest queue. It is the one that understands what kind of deep learning work is in front of it, what resources it truly needs, and what trade-off the cluster is willing to make.
Paper: Deep Learning Workload Scheduling in GPU Datacenters: A Survey
Project: Awesome DL Scheduling Papers
Zhisheng YE
Machine Learning Systems Researcher
My research interests include AI Infra for LLMs, algorithm–system co-design for machine learning systems and resource management.