Chronus: A Novel Deadline-aware Scheduler for Deep Learning Training Jobs
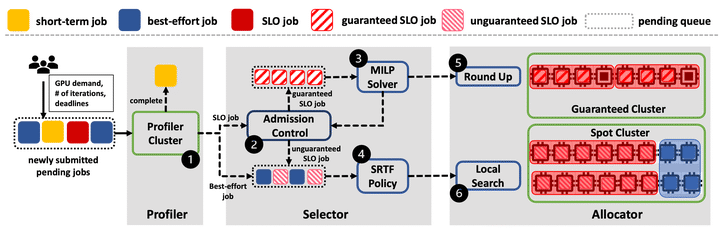 System design
System design
Abstract
Modern GPU clusters support Deep Learning training (DLT) jobs in a distributed manner. Job scheduling is the key to improve the training performance, resource utilization and fairness across users. Different training jobs may require various objectives and demands in terms of completion time. How to efficiently satisfy all these requirements is not extensively studied. We present Chronus, an end-to-end scheduling system to provide deadline guarantee for SLO jobs and maximize the performance of best-effort jobs. Chronus is designed based on the unique features of DLT jobs. (1) It leverages the intra-job predictability of DLT processes to efficiently profile jobs and estimate their runtime speed with dynamic resource scaling. (2) It takes advantages of the DLT preemption feature to select jobs with a lease-based training scheme. (3) It considers the placement sensitivity of DLT jobs to allocate resources with new consolidation and local-search strategies. Large-scale simulations on real-world job traces show that Chronus can reduce the deadline miss rate of SLO jobs by up to 14.7x, and the completion time of best-effort jobs by up to 19.9x, compared to existing schedulers. We also implement a prototype of Chronus atop Kubernents in a cluster of 120 GPUs to validate its practicability.
Zhisheng YE
Machine Learning Systems Researcher
My research interests include AI Infra for LLMs, algorithm–system co-design for machine learning systems and resource management.