Tear Up the Bubble Boom: Lessons Learned From a Deep Learning Research and Development Cluster
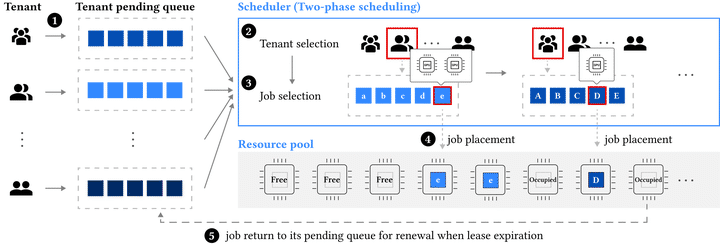 System design
System design
Abstract
With the proliferation of deep learning, there exists a strong need to efficiently operate GPU clusters for deep learning production in giant AI companies, as well as for research and development (R&D) in small-sized research institutes and universities. Existing works have performed thorough trace analysis on large-scale production-level clusters in giant companies, which discloses the characteristics of deep learning production jobs and motivates the design of scheduling frameworks. However, R&D clusters significantly differ from production-level clusters in both job properties and user behaviors, calling for a different scheduling mechanism. In this paper, we present a detailed workload characterization of an R&D cluster, CloudBrain-I, in a research institute, Peng Cheng Laboratory. After analyzing the fine-grained resource utilization, we discover a severe problem for R&D clusters, resource underutilization, which is especially important in R&D clusters while not characterised by existing works. We further investigate two specific underutilization phenomena and conclude several implications and lessons on R&D cluster scheduling. The traces will be open-sourced to motivate further studies in the community.
Zhisheng YE
Machine Learning Systems Researcher
My research interests include AI Infra for LLMs, algorithm–system co-design for machine learning systems and resource management.