 System design
System design
Abstract
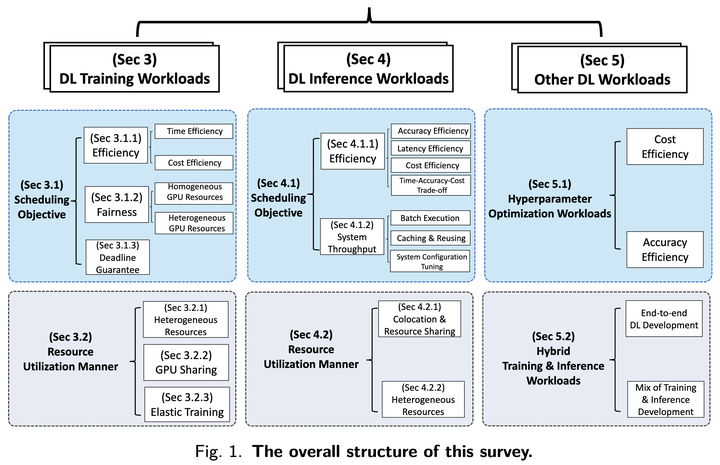
Deep learning (DL) shows its prosperity in a wide variety of fields. The development of a DL model is a time-consuming and resource-intensive procedure. Hence, dedicated GPU accelerators have been collectively constructed into a GPU datacenter. An efficient scheduler design for such GPU datacenter is crucially important to reduce the operational cost and improve resource utilization. However, traditional approaches designed for big data or high performance computing workloads can not support DL workloads to fully utilize the GPU resources. Recently, substantial schedulers are proposed to tailor for DL workloads in GPU datacenters. This paper surveys existing research efforts for both training and inference workloads. We primarily present how existing schedulers facilitate the respective workloads from the scheduling objectives and resource consumption features. Finally, we prospect several promising future research directions. More detailed summary with the surveyed paper and code links can be found at our project website: this https URL.
Zhisheng YE
Machine Learning Systems Researcher
My research interests include AI Infra for LLMs, algorithm–system co-design for machine learning systems and resource management.