UniSched: A Unified Scheduler for Deep Learning Training Jobs with Different User Demands
 System design
System design
Abstract
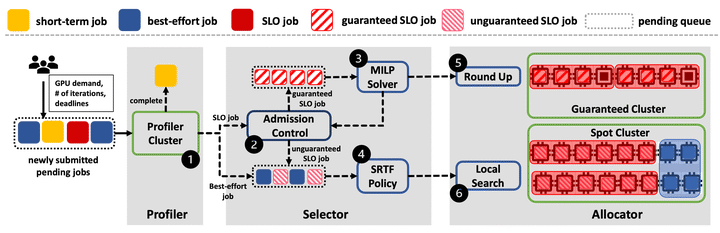
The growth of deep learning training (DLT) jobs in modern GPU clusters calls for efficient deep learning (DL) scheduler designs. Due to the extensive applications of DL technology, developers may have different demands for their DLT jobs. It is important for a GPU cluster to support all these demands and efficiently execute those DLT jobs. Unfortunately, existing DL schedulers mainly focus on part of those demands, and cannot provide comprehensive scheduling services. In this work, we present UniSched, a unified scheduler to optimize different types of scheduling objectives (e.g., guaranteeing the deadlines of SLO jobs, minimizing the latency of best-effort jobs). Meanwhile, UniSched supports different job stopping criteria (e.g., iteration-based, performance-based). UniSched includes two key components: Estimator for estimating the job duration, and Selector for selecting jobs and allocating resources. We perform large-scale simulations over the job traces from the production clusters. Compared to state-of-the-art schedulers, UniSched can significantly decrease the deadline miss rate of SLO jobs by up to 6.84X, and the latency of best-effort jobs by up to 4.02X, To demonstrate the practicality of UniSched, we implement and deploy a prototype on Kubernetes in a physical cluster consisting of 64 GPUs.
Zhisheng YE
Machine Learning Systems Researcher
My research interests include AI Infra for LLMs, algorithm–system co-design for machine learning systems and resource management.