木叶吟
木叶吟
Home
Experience
Posts
Publications
Services
CV
Light
Dark
Automatic
English
中文 (简体)
LLM Training
OctoPipe: Reducing Pipeline Bubbles for Heterogeneous Models via Co-Optimizing Partitioning, Placement, and Scheduling
We propose OctoPipe, a novel pipeline parallelism system that reduces pipeline bubbles on heterogeneous models by co-optimizing partitioning, placement, and scheduling, achieving 1.22-2.14x throughput improvement over Megatron-LM.
Jihu Guo
,
Tenghui Ma
,
Wei Gao
,
Peng Sun
,
Xun Chen
,
Jiaxing Li
,
Zhisheng YE
,
Yuyang Jin
,
Dahua Lin
Preprint
PDF
Cite
Helix: Automating Communication-Computation Overlap with Graph Scheduling
A technical note on Helix, a compiler-based graph scheduling system that overlaps communication and computation for n-D model parallel training and inference.
Zhisheng YE
May 18, 2026
9 min read
ResiHP: Surviving LLM Training Failures with Dynamic Hybrid Parallelism
A technical report on ResiHP, a resilient training system that detects fail-slow devices under noisy sequence-length variation and dynamically adapts 3D parallelism.
Zhisheng YE
May 17, 2026
3 min read
ResiHP:大模型训练故障下的动态混合并行
一篇关于 ResiHP 的技术报告:它在变长序列带来的噪声中识别 fail-slow 设备,并动态调整 3D 并行来提升大模型训练韧性。
Zhisheng YE
May 17, 2026
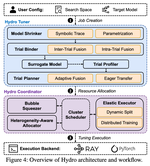
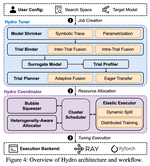
Hydro: Squeezing Hyperparameter Tuning into Pipeline Bubbles
A technical story behind Hydro’s Bubble Squeezer, which runs surrogate hyperparameter tuning trials inside the idle bubbles of pipeline-parallel large-model training.
Zhisheng YE
May 17, 2026
8 min read
Hydro:把超参数搜索放进流水线空泡
一篇关于 Hydro Bubble Squeezer 的技术文章:它把轻量级超参数搜索任务放进大模型流水线并行训练的空泡里运行。
Zhisheng YE
May 17, 2026
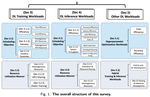
GPU Cluster Scheduling: A Map for Deep Learning Workloads
A technical guide to GPU datacenter scheduling based on our ACM Computing Surveys paper, covering training, inference, HPO, mixed workloads, and future scheduler design.
Zhisheng YE
May 16, 2026
7 min read
ResiHP: Taming LLM Training Failures with Dynamic Hybrid Parallelism
Hybrid parallelism underpins large-scale LLM training across tens of thousands of GPUs. At such scale, hardware failures on individual …
Tenghui Ma
,
Jihu Guo
,
Wei Gao
,
Sitian Lu
,
Zhisheng YE
,
Dahua Lin
,
Hanjing Wang
Preprint
Cite
DOI
Characterization of Large Language Model Development in the Datacenter
Large Language Models (LLMs) have presented impressive performance across several transformative tasks. However, it is non-trivial to …
Qinghao Hu
,
Zhisheng YE
,
Zerui Wang
,
Guoteng Wang
,
Meng Zhang
,
Qiaoling Chen
,
Peng Sun
,
Dahua Lin
,
Xiaolin Wang
,
Yingwei Luo
,
Yonggang Wen
,
Tianwei Zhang
Preprint
Cite
AMSP: Super-Scaling LLM Training via Advanced Model States Partitioning
Large Language Models (LLMs) have demonstrated impressive performance across various downstream tasks. When training these models, …
Qiaoling Chen
,
Qinghao Hu
,
Zhisheng YE
,
Guoteng Wang
,
Peng Sun
,
Yonggang Wen
,
Tianwei Zhang
Preprint
Cite
»
Cite
×