CONCUR:让 Agent 批量推理避开中期拥塞
过去的 LLM 批量推理主要围绕请求组织。一个请求到达后,服务端调度 prefill 和 decode,为这条序列维护 KV cache,请求结束后再释放相关状态。
Agentic workload 不一样。一个 agent 不是一次请求,而是一个长时间运行的循环:planning、tool call、observation,然后继续 generation。许多 agent 可以同时存活,并逐步累积自己的 KV state。服务端看到的仍然是一个个请求,但真正制造资源压力的是 agent 的生命周期。
CONCUR 关注的就是这种场景下出现的一类病理现象:mid-phase thrashing。
什么是中期抖动
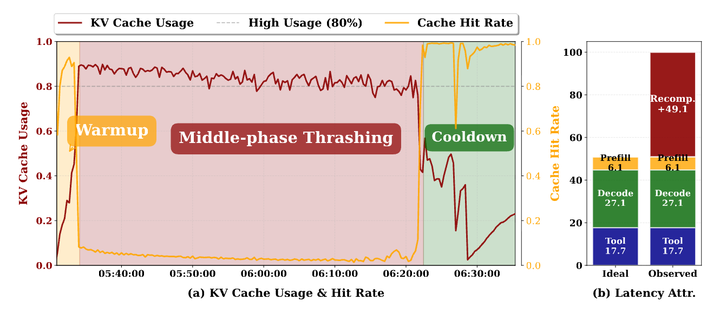
一批长时间运行的 agent 并不会一开始就失败。刚开始时,大多数 agent 的上下文还很短,KV cache 需求有限,吞吐看起来很健康。接近结束时,很多 agent 已经完成,压力也会下降。
真正困难的是中期:大量 agent 仍然活跃,而且它们的上下文已经明显增长。整体 KV cache footprint 变得很大,但 GPU memory 可能还没有被完全耗尽。这让问题很隐蔽:单看容量检查,系统似乎还能运行;但从 cache efficiency 看,它已经接近失控。
当 KV pressure 跨过某个阈值后,请求级 cache 管理会开始和自己打架。Serving system 可能会为了给新内容腾空间而 evict 旧的 KV blocks。但 agentic workload 很快又会回到这些被 evict 的历史,因为同一个 agent 会继续生成、调用工具、再继续推理。于是服务端不得不重新计算或重新加载上下文,消耗 GPU 时间,并带来更多 cache churn。更多 churn 导致更多 eviction,更多 eviction 又导致更多 recomputation。内存容量还没正式耗尽,吞吐已经先崩了。
这就是 mid-phase thrashing。
为什么只管请求已经太晚
根因是控制粒度错位。Serving runtime 管的是单个请求,但压力来源是活跃 agent 的数量。
如果一开始放进来的 agent 太多,每个 agent 都会继续增长自己的上下文。Reactive cache policy 只能在 KV cache 已经拥塞之后再反应。LRU 这类 eviction 对单个请求流可能局部合理,但对 agentic workload 来说不是一个好的全局信号。它不知道某个被 evict 的 block 属于一个仍然存活的 agent,而这个 agent 很可能很快又需要它。
换句话说,系统并不只是“内存不够了”。它是把太多长生命周期的 state machine 同时放进了一个共享 cache。
CONCUR 把问题从“现在该 evict 哪个 KV block”改写成“同一时间应该允许多少 agent 保持活跃”。
| 控制点 | 它看到什么 | 为什么太晚或有用 |
|---|---|---|
| 请求级 cache policy | 单个 KV block 和请求流 | 拥塞已经发生之后才反应 |
| 静态 batch size | 初始 workload 形状 | 看不到 agent 历史会随时间增长 |
| Agent-level admission | 长生命周期活跃 agent 数量 | 直接作用在累积状态的实体上 |
在 Agent 层做准入控制
CONCUR 在 LLM serving engine 上方加入了一个轻量控制层。它不替换后端 cache manager,而是调节 agent admission,让活跃 agent 的整体压力停留在 cache efficiency 崩溃点之前。
这个设计借鉴了 congestion control 的思路。KV cache 被视为共享瓶颈资源,并发活跃 agent 数量就是 control window。当运行时 cache signal 表明系统健康时,CONCUR 增加并发,进一步利用容量;当 signal 显示系统开始拥塞时,它会在抖动失控之前退让。
这更接近 AIMD-style control,而不是静态 batching。Additive increase 让系统谨慎探索更多并行度,multiplicative decrease 则在 cache pressure 变危险时快速反应。关键细节是,控制单位是 agent,而不是请求。暂停接纳新 agent 可以保留已经进入系统的 agent 的执行连续性,也避免反复 evict 它们很快还会复用的历史。
这种主动控制还保持了兼容性。已有 LLM serving system 仍然可以在内部管理请求调度和 KV placement。CONCUR 只根据 cache-aware feedback 决定 active set 中允许存在多少 agent。
为什么有效
Mid-phase thrashing 的根源是累积状态压力,所以解决方案必须在 cache 进入 thrashing regime 之前介入。通过约束活跃 agent 数量,CONCUR 减少了同一时间争抢 KV cache 的长生命周期上下文。系统可能同时跑更少 agent,但每个活跃 agent 经历的 eviction 和 recomputation 更少,所以有效 generation throughput 反而提升。
论文报告显示,CONCUR 可以在大模型和真实 agent workload 上避免 mid-phase thrashing,并将批量推理吞吐在 Qwen3-32B 上最多提升 4.09x,在 DeepSeek-V3 上提升 1.9x。
CONCUR 换来了什么。
- 避免 eviction/recomputation 反馈循环造成的中期吞吐崩溃。
- 在 Qwen3-32B 上将 batch inference throughput 最多提升 4.09x。
- 在 DeepSeek-V3 上将 throughput 提升 1.9x。
这里的经验很简单,但很容易忽略:对于 agentic inference,正确的调度对象不一定总是请求。有时候请求只是表象。真正累积状态、持续消耗 cache、并一遍遍回到同一段历史的实体是 agent。CONCUR 让 serving system 看见了这个实体。
Paper: CONCUR: High-Throughput Agentic Batch Inference of LLM via Congestion-Based Concurrency Control
Preprint: arXiv:2601.22705