GPU 集群调度:深度学习任务该如何排队、放置与共享
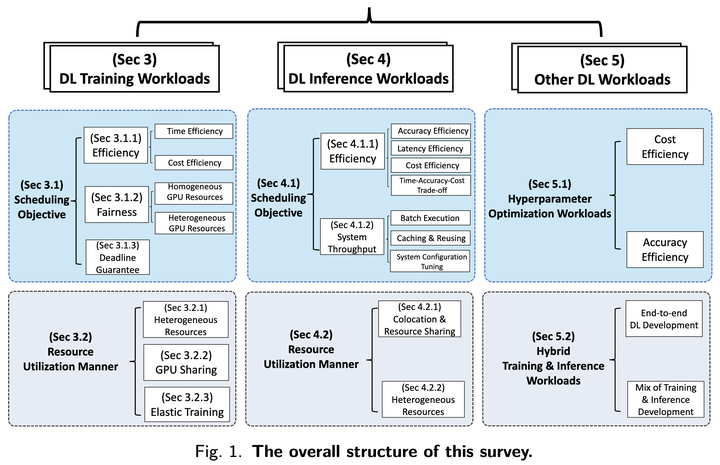 A taxonomy of deep learning workload scheduling in GPU datacenters
A taxonomy of deep learning workload scheduling in GPU datacenters
GPU 集群调度很容易被低估。乍看起来,它像一个熟悉的资源分配问题:任务到达,GPU 有空闲也有忙碌,调度器决定谁先运行。
深度学习打破了这种简单性。
训练任务可能运行好几天,需要成组 GPU,并且对 placement topology 非常敏感。推理服务是在线服务,对 latency 敏感,如果不做 batching 或 colocation,往往又难以充分利用 GPU。超参数搜索会启动大量相似 trial,其中大多数注定会被丢弃。LLM workload 还会带来 model parallelism、巨大的 memory footprint、long context,以及开发过程中的 bursty pattern。
我们的 survey,Deep Learning Workload Scheduling in GPU Datacenters,试图整理这个复杂的设计空间。理解这个领域最有用的方式,不是把调度器列成清单,而是看它们面对的一组张力:速度与成本、利用率与隔离、公平性与效率、在线 latency 与集群整体吞吐。
为什么深度学习调度不一样
传统 HPC 和大数据调度器提供了有用起点,但深度学习任务有自己的物理规律。
训练任务往往需要 gang scheduling。一个分布式任务必须同时拿到所有请求的 GPU,因此 GPU 不像 CPU slot 那样容易切分。Placement 很重要,因为通信密集型任务如果被放在同一节点内或通过 NVLink 连接,可能比散落在弱链路上快得多。抢占很昂贵,因为模型和优化器状态都很大。同时,训练又具有迭代性,所以少量 profiled iteration 往往能暴露 throughput、memory behavior 和 placement sensitivity。
推理的压力几乎相反。每个请求相比训练任务很小,但服务有 latency SLO。Batching 可以提高 GPU utilization,但等待组 batch 会增加用户可见 latency。Colocation 可以提升 throughput,但 interference 可能打破 tail latency。调度器必须在平均效率和最坏情况下的用户体验之间做取舍。
这就是为什么 GPU 集群调度不是一个单一问题。它是一组相关问题,正确答案取决于工作负载。
训练:效率、公平性、Deadline
对于训练任务,survey 把调度目标分成三大类。
第一类是效率。有些调度器通过 priority rule 降低任务完成时间,比如 least attained service 或 progress-aware variant。另一些调度器使用 profiling 或 learning-based method 预测任务时长、速度、placement sensitivity 或未来资源需求。Placement 是效率的核心部分:一个调度器可能在总量上有足够 GPU,却因为集群碎片化而无法满足 locality,导致性能很差。
第二类是公平性。公平性很微妙,因为在常见 gang-scheduling 场景中 GPU 不可分割,而异构 GPU 对不同任务的价值也不一样。Finish-time fairness、long-term GPU-time fairness 和 heterogeneity-aware fairness 都在回答同一个问题的不同版本:这个任务或租户应得多少 service,实际又获得了多少?
第三类是 deadline guarantee。Deadline-aware training 研究相对少,但对生产流程很重要。Best-effort 任务可以容忍等待;SLO 任务不行。这类系统需要预测某个任务在不同 placement 和 resource allocation 下能否按 deadline 完成,再决定如何混合 deadline 任务和普通任务。
训练:GPU 如何被使用
目标只是 taxonomy 的一半,另一半是调度器如何使用资源。
Heterogeneous resource scheduling 认识到“一张 GPU”并不是一个统一单位。不同 model architecture 对新一代 GPU、CPU allocation、memory、network bandwidth 和 storage 的收益不同。一个 cost-effective 调度器应该把任务放到和其 bottleneck 匹配的硬件上,而不是盲目把所有任务都送到最新设备。
GPU sharing 试图解决 underutilization 问题。许多训练任务无法吃满现代 GPU。通过 MPS、MIG、virtualization、time sharing 或 framework-level co-execution,把多个任务打包到同一设备上可以提高利用率。风险是 interference:调度器必须知道什么时候 sharing 有收益,什么时候它只是悄悄拖慢所有任务。
Elastic training 会随时间改变分配给任务的 GPU 数量。在需求波动时,它可以减少排队并提升利用率。但 elasticity 不是免费的。资源变化可能需要 checkpoint、reinitialization 或 batch-size adaptation。如果 batch size 的变化影响 convergence,调度器可能提升了系统 throughput,却悄悄改变了模型行为。
一个大趋势是,训练调度器越来越需要和训练框架协同设计。调度器想要细粒度控制,但框架才知道一个任务是否能安全 pause、resize、share 或改变 batch size。
推理:Latency、成本、Throughput
推理调度由另一组三角关系塑造:latency、cost 和 accuracy。
Latency 通常是一等约束。Model serving system 可以通过 batching 提升 throughput,但请求在队列里等待本身就是用户可见 latency。实际调度器往往使用 dynamic batching:服务健康时增大 batch size;latency 接近 SLO 时缩小 batch。
Cost 来自 cloud instance selection、autoscaling 和 heterogeneous hardware。有些工作负载在 CPU 上更便宜,有些需要 GPU,还有些只有在 batch 足够大时才划算。调度器不仅要决定模型放在哪里,还要决定需要多少 replica、哪些 instance type 值得付费。
Accuracy 又引入了一个维度。有些系统会在 model variant、ensemble 或 modality 之间选择。小模型便宜快速但准确率较低;大模型更慢但效果更好。这让推理调度变成 policy problem:在给定 latency 或 cost budget 下,可以接受多大 accuracy loss?
Throughput 技术包括 batching、caching、model residency 和 colocation。但推理 colocation 比训练 colocation 更危险,因为 SLO violation 是即时可见的。调度器需要 interference model、isolation mechanism 或 hardware partitioning,才能让 sharing 安全。
训练和推理之外
有些工作负载值得单独分类。
Hyperparameter optimization 技术上属于训练,但在操作上很不一样。它会启动许多相似 trial,提前剪枝较弱的 trial,并把资源转向更有前途的 configuration。这种结构带来了 early stopping、elastic trial allocation、trial packing、model fusion 和 surrogate-based tuning 的机会。我们的 Hydro 工作就是一个例子:它用 model scaling、trial fusion 和 cluster-level interleaving 让 HPO 少一点 brute force。
混合训练和推理工作负载是另一个前沿。推理集群往往为了应对 burst 而过度配置,在低流量期间留下 idle GPU。如果系统能在推理需求回来时快速 preempt 或 resize 训练任务,训练就可以借用这部分容量。挑战是,在回收空闲资源的同时仍然尊重在线 SLO。
这些例子指向一个更大的趋势:未来调度器会越来越 workload-aware。面对深度学习开发的多样性,一个泛泛的 GPU queue 已经太粗糙。
这个领域正在走向哪里
Survey 最后总结了三个至今仍然重要的研究方向。
第一,emerging workload 会继续改变调度器设计。LLM pretraining、fine-tuning、serving、agentic inference 和 HPO 都暴露出不同瓶颈。调度器需要理解的不只是 GPU 数量,还包括 memory pressure、communication structure、context length、trial similarity 和 elasticity。
第二,调度决策需要更好的智能。Heuristic 鲁棒且容易部署,mathematical optimization 更有原则但可能很慢,ML/RL-based scheduler 能捕捉复杂 pattern 但难以信任和 benchmark。实际调度器可能会结合三者:fast path 用 heuristic,profiling 用于校准,复杂决策再交给 optimization 或 learning。
第三,hardware heterogeneity 已经不可避免。生产集群可能包含多代 GPU、专用 interconnect、CPU、storage tier 和 accelerator。异构性带来更好的 cost-performance 机会,但也让公平性更复杂。给一个任务分配老 GPU 和新 GPU,即使用时相同,也很少代表相同服务。
最简单的总结是:GPU 调度已经不再只是填满空 slot。它是在用户可见目标之下,把工作负载结构匹配到硬件结构。
这也是这个方向有意思的地方。最好的调度器不只是队列最短的那个,而是理解眼前的深度学习任务是什么、真正需要什么资源,以及集群愿意做出什么 trade-off 的那个。
Paper: Deep Learning Workload Scheduling in GPU Datacenters: A Survey
Project: Awesome DL Scheduling Papers