Helix:用图调度自动化通信-计算重叠
大模型很少只靠一种干净的并行策略训练或推理。Tensor parallelism 切分矩阵计算,pipeline parallelism 切分模型层,sequence parallelism 把长上下文分散到多张卡上,expert parallelism 则把 token 路由到分布式 expert。真实部署里,这些维度往往会组合在一起。
这种组合很强,但也带来一个熟悉的系统成本:通信空泡。 当 AllReduce、AllGather、ReduceScatter 或 All-to-All 落在关键路径上时,GPU 计算单元就在等待。在 dense tensor-parallel block 里,等待可能来自 sharded matrix result;在 long-context sequence-parallel block 里,等待可能来自 sequence chunk 交换;在 MoE layer 里,等待可能来自跨 expert 的 token routing。并行策略不同,但问题形状相同:计算和通信都存在,只是执行图没有暴露出足够多可以安全重叠的机会。
Helix 的核心想法是:communication-computation overlap 应该是一个图调度问题,而不是每遇到一种新并行模式就重新手写一套 kernel trick。Helix 目前是一个从 2026 年初开始的 WIP research project,后续会继续更新。
为什么手写重叠难以扩展
最快的 overlap 技术通常会深入 kernel。它们把一个操作切成小块,提前发起通信,并把足够多的计算融合进去以隐藏通信延迟。对单一模式来说,这种方法可以非常有效。Ring-style attention 可以把 sequence exchange 和本地 attention block 重叠起来;tensor-parallel kernel 可以把 collective 和 partial matrix multiplication 做流水;MoE 系统也可以围绕 token dispatch 调度 expert computation。
问题在于,这类优化往往把模型、collective、tiling shape 和同步协议的假设都写进了实现。一旦模型结构变化,或者部署同时组合 tensor、sequence、expert parallelism,优化就很难复用。更重要的是,局部技巧可能会错过全局机会:某个并行维度产生的通信,本来可以藏到另一个并行维度的计算下面,但 pattern-specific optimizer 未必看得见。
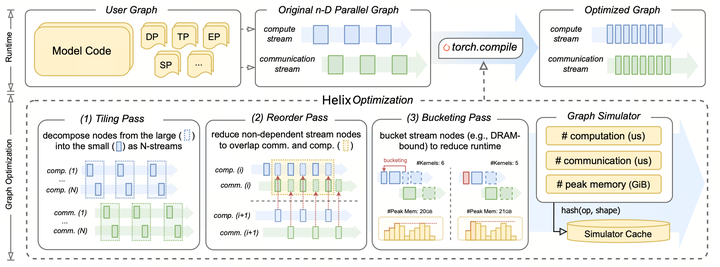
Helix 把优化边界上移到编译后的执行图。torch.compile 捕获 model-parallel program 后,Helix 可以在同一个 intermediate representation 里看到 compute operator、communication operator、wait 和 dependency edge。这个统一图抽象是关键。编译器不再需要为每一种并行策略写单独的 overlap recipe;只要节点在图里可见、依赖关系明确,就可以在同一套正确性规则下调度它们。
调度目标
从高层看,Helix 把 model-parallel program 看成一张有向图。节点是 compute 或 communication operator,边是 precedence constraint:一个 operator 只有在依赖的数据准备好之后才能运行。
优化目标很直接,但有约束:
- 通过把通信藏到独立计算下面,降低图的 makespan;
- 保留原始图中的所有数据依赖;
- 把 peak memory 控制在设备可用预算内。
最后一点很重要。激进 overlap 并不是免费的。如果编译器过早 launch 太多 work,中间 activation 和 communication buffer 的生命周期会变长。一个时间线上看起来更快的 schedule,可能因为 peak memory 膨胀而无法运行。因此 Helix 同时优化时间和内存,并用一个轻量 graph simulator 来指导决策。
系统主要包含三个 compiler pass:tiling、reordering 和 bucketing。
| Pass | 改变什么 | 保护什么 |
|---|---|---|
| Tiling | 把粗粒度 operator 切成 tile stream | 制造 overlap 机会,同时保持局部依赖 |
| Reordering | 围绕 wait 交织不同 tile stream 的 segment | 提前通信,同时保留同步语义 |
| Bucketing | 把兼容的碎片重新合并 | 在 memory budget 下拿回 kernel efficiency |
Tiling:制造重叠机会
原始执行图通常太粗。一个大的 compute operator 可能必须等待一个大的 communication operator,即使这些工作本来可以拆成小块交错执行。Helix 的第一步是 graph tiling:把 operator 切分成多个 tile stream,同时保留每个 stream 内部的依赖结构。
默认情况下,论文沿 batch dimension 做 tiling,因为它适用范围广,也更容易保证正确性。在某些 correctness 已经明确的图区域里,也可以沿 sequence length 等其他维度切分。
Tiling 有两个收益。第一,它暴露 overlap。一个 tile stream 的通信可以在另一个 tile stream 的计算还在运行时提前发起,从而把一张刚性的图变成几条可以交织调度的小流。第二,它可以降低 activation memory。tile 变小后,同时存活的 input 和 intermediate tensor 也更小,只要生命周期控制得当,peak memory 就会下降。
但 tiling 也有代价。更小的 compute kernel 可能损失效率,尤其是 normalization、softmax 和 pointwise function 这类 memory-bound operator。更小的通信消息也可能降低有效带宽。论文里的 profiling 显示,小 tiling factor 通常是更实际的选择;Helix 默认使用 K = 2,因为它能暴露足够 overlap,同时避免过度碎片化。
Reordering:安全地实现重叠
Tiling 之后,编译器得到多条相对独立的 tile stream。接下来的问题是 launch order。
朴素 schedule 会把这些 stream 逐条执行。这当然正确,但会留下通信空泡。过于激进的 schedule 则会提前 launch 大量 asynchronous operator,虽然可能增加 overlap,却也会让太多 tensor 同时存活,推高 peak memory。
Helix 使用 Segmented Round-Robin Reordering,在两者之间取平衡。关键观察是,显式 wait operator 天然就是 segment boundary。在一条 tile stream 内,Helix 会把连续的 non-blocking compute 和 communication operator 组成一个 segment,直到遇到 wait。之后,它以 round-robin 的方式在多条 stream 之间调度这些 segment。这样,一个 stream 的通信可以被插入另一个 stream 的 compute-heavy 区间,而 wait 仍然保证原始数据依赖不被破坏。
Scheduler 只在 wait 之间积极重排;wait operator 保留了原始依赖契约。
Segment 级粒度很关键。它比逐 operator eager scheduling 更粗,因此不会让大量中间结果同时挂起;segment 在同步边界被 flush 后,其中间 tensor 可以及时释放。它又比完全串行执行更细,因此能把通信提前到原始图中无法利用的位置。
这也是 Helix 泛化性的重要来源。调度器不需要关心某个节点来自 tensor parallelism、sequence parallelism 还是 expert parallelism。只要节点在图中可见,依赖关系是显式的,reordering pass 就可以对它做统一推理。
Bucketing:把 kernel 效率拿回来
Tiling 创造了灵活性,但过度碎片化会伤害硬件效率。Bucketing pass 负责有选择地修复这种损伤。
它的想法是,在确实能提升端到端性能时,把不同 tile stream 中兼容的 operator 重新合并成更大的 bucket。这听起来简单,但里面有 trade-off。Bucketing 可以降低 kernel launch overhead,也可以改善计算或通信效率;但它也可能重新引入同步、减少调度自由度,并因为把某些 work 提前而延长 tensor 生命周期。
Helix 把 bucketing 看成一个 constrained search。对一个 candidate merge,graph simulator 会估计两个量:新的 makespan 和新的 peak memory。只有当节省的时间值得额外内存成本,并且不会破坏 tiling 和 reordering 已经创造出的关键 overlap 时,这个 merge 才有价值。实现上,系统用 dynamic programming 在 candidate bucket 中选择一组最优 merge,使 schedule 在 memory budget 内获得更好性能。
这个 pass 让 Helix 不只是“全部切碎然后祈祷”。它先主动制造 overlap 粒度,再把不该碎着运行的部分融合回来。
Simulator 是控制回路
Graph simulator 很轻量,但很核心。它在编译期运行,用来估计候选 schedule 的 runtime 和 peak memory。对 compute 和 communication cost,它结合图中可见的 operator semantics、tensor shape、analytical modeling 和自动 benchmark。对 memory,它模拟执行顺序,并追踪 tensor 和 communication buffer 的生命周期。
| Simulator 估计项 | Optimizer 为什么需要 |
|---|---|
| Candidate makespan | 判断 schedule 是否真的隐藏了通信 |
| Peak memory | 拒绝制造过多长生命周期 tensor 或 buffer 的 schedule |
| Operator 和 communication cost | 在真实执行前比较 tiling、reordering、bucketing 选择 |
Simulator 不需要完美才有用。它只需要足够准确地给 scheduling choice 排序,让编译器避开明显糟糕的 trade-off。论文报告显示,在 GPT-3、LLaMA3 和 Qwen3-MoE 的配置上,估计结果和真实 trace 比较接近。例如在一个 GPT-3 Curie 配置中,estimated runtime 是 6.80 秒,真实 measured runtime 是 6.41 秒;estimated peak memory 是 65.9 GiB,真实值是 66.0 GiB。
这种 fidelity 很重要,因为 optimizer 必须在真实运行前做决定。没有 simulator,编译器要么需要昂贵的 trial execution,要么只能依赖脆弱的 heuristic。
Helix 带来了什么
在 GPT-3、LLaMA3 和 Qwen3-MoE workload 上,Helix 展现出一致模式:一旦通信被暴露给图调度,bubble 会缩小,有效 GPU work 会增加。端到端训练吞吐在单节点内提升 4% 到 9%;当通信跨节点时,收益扩大到 12% 到 30%。在 layer level,communication bubble 通常减少超过 60%,这直接说明 scheduler 确实在隐藏通信,而不是简单把开销挪到别处。
Helix 换来了什么。
- 单节点内端到端训练吞吐提升 4% 到 9%。
- 跨节点通信场景下吞吐提升 12% 到 30%。
- 许多场景下 layer-level communication bubble 减少超过 60%。
- Long-context inference activation memory 最多减少 30%。
内存收益同样重要。在 long-context inference 中,Helix 最多减少 30% activation memory,在 measured trace 中把 peak memory 从 23.5 GiB 降到 21.4 GiB。这和性能收益来自同一个设计原则:graph scheduler 控制 tile 什么时候变成 live、其中间结果什么时候可以释放,而不是让 overlap 意外拉长 memory lifetime。
和手写 tensor-parallel overlap 的对比也很有意思。在大规模 GPT 和 LLaMA 训练中,Helix 相对 baseline 达到 17% 和 16% speedup,而 AsyncTP 在同一对比中是 12% 和 13%。这并不是说 compiler scheduling 会让 specialized kernel 过时;更重要的是,graph-level optimizer 可以在同一个地方同时处理跨维度 overlap、正确性、同步、kernel efficiency 和 memory lifetime。
Helix 的技术核心就是这件事:让通信在图里可见,让依赖关系显式化,然后让编译器去调度那些原本需要为每个 workload 手工重新发现的 overlap。